
The Problem This Solves
AI quality cannot be managed by vibes. As models change, prompts evolve, users find edge cases, and workflows become more autonomous, teams need a way to measure behavior and enforce policy. Without that layer, every release becomes a judgment call and every failure becomes a surprise.
Guardrails are often added too late or too narrowly. A moderation endpoint alone does not solve privacy, prompt injection, source misuse, unsafe tool calls, hallucinated claims, toxic output, regulated advice, or auditability. Production AI needs layered controls that match the actual risk profile of each workflow.
How Vertex Builds It
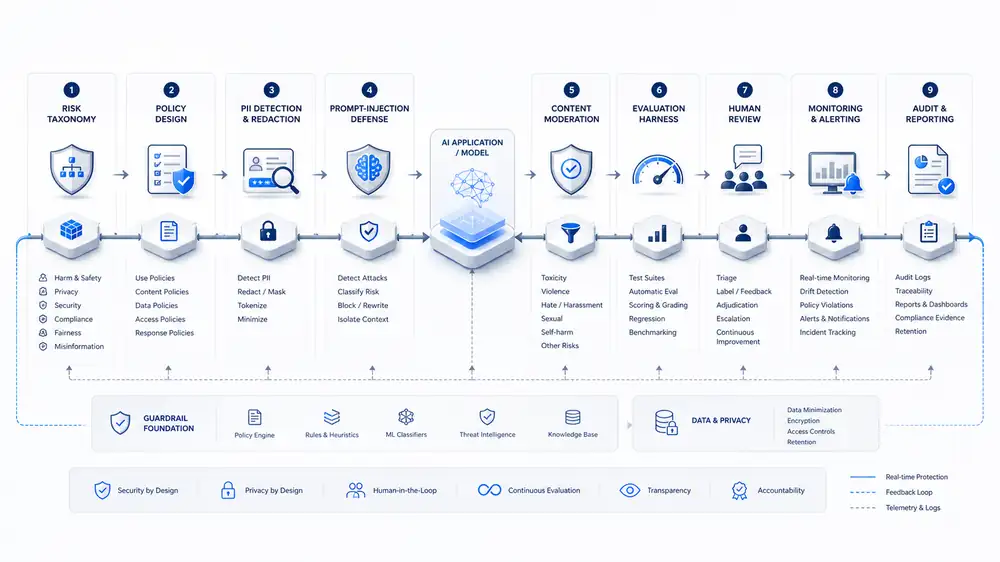
Vertex begins with a risk taxonomy for the AI system: what the model can see, say, decide, and do. We identify sensitive data, regulated content, unacceptable outputs, high-risk actions, and the business consequences of failure. That taxonomy becomes the basis for guardrails and evaluations.
We then implement the control layer: input filters, PII redaction, prompt-injection checks, retrieval constraints, output validation, tool-use policies, human review queues, monitoring, incident workflows, and automated evals. The aim is not to block useful AI. The aim is to make useful AI measurable, governable, and release-ready.
Where It Fits
Evaluation harnesses for LLM apps, RAG systems, and AI agents.
PII detection and redaction before model calls or logging.
Prompt-injection and jailbreak resistance for tool-using systems.
Moderation and policy enforcement for user-facing AI features.
Architecture & Delivery Flow
The delivery flow is intentionally practical: validate the business case, identify the riskiest technical assumptions, build the smallest useful production path, and then harden the operating model so the system can be owned after launch.
Expected Outcomes
Higher confidence in AI releases through repeatable evaluation.
Reduced privacy and compliance exposure through data controls.
Fewer unsafe outputs through layered input, retrieval, and output checks.
Better incident response because logs, traces, and audit evidence exist.
Faster AI delivery because teams can ship against measurable quality gates.
Frequently Asked Questions
Are guardrails only for customer-facing chatbots?
No. Internal copilots, RAG systems, agents, document workflows, and automation pipelines also need controls when they handle sensitive data or high-impact decisions.
Can guardrails eliminate hallucinations?
No system can guarantee that, but guardrails and evaluations can reduce risk, detect failures, constrain outputs, and route uncertain cases to review.
How do evals fit into release management?
Each model, prompt, retrieval, or policy change should run against defined test sets and thresholds before release, with regression visibility over time.
Will safety controls make the AI less useful?
Good controls are risk-calibrated. They should block unsafe behavior while preserving useful workflows through better routing, clearer fallbacks, and human review where needed.